Accendo > Publikované > MSSQL Performance Troubleshooting
Autor: Libor Bešenyi
Dátum: 2013/03/26
Zmena: 2013/04/17
MSSQL Performance Troubleshooting
Tento článok bude nejaký rýchly introduce do MSSQL performance troubleshootingu (s nástrojmi, ktoré sú dostupné v systéme). Chcem upozorniť, že nie som orientovaný na databázy, takže postupy a myšlienky môžu byť naivné, ale takýmto spôsobom sa nám skutočne podarilo identifikovať a upraviť slabe miesta v systéme.
To, že nám kolabuje server sme zistili rýchlo. Zákazníci volali na support v takých šialených množstvách, až sa niekto z nás prihlásil na server a každá jedna operácia (ako otvorenie task managera) bola fakt zúfalo dlhá. CPU šiel nepretržite na 100% (EKG umierajúceho servera):

Definícia kritérii
Každá zmena musí byť merateľná a ak chceme stanoviť ciele – nemôžeme si ich vymyslieť z brucha, lebo úlohu nevyriešime a len demotivujeme tím! Preto sme začali merať stav, aby sme vedeli definovať ciele úspechu optimalizácie.
Zistili sme, že peak-time u nás nastával od desiatej hodiny a trval do druhej. Potom od tretej do siedmej. Vtedy šlo DB CPU bez prestávky na 100%.
Základom je samozrejme DB údaj – page expectancy. Tento údaj hovorí, ako dlho sa drží stránka v pamäti. Čím vyššie číslo, tým lepšie. Pretože to znamená, že v podstate všetko s čím databáza pracuje je nacachované. U nás to číslo bolo hrozivých 8. Query na zistenie je tu:
select
cntr_value
from sys.dm_os_performance_counters
where
object_name LIKE '%Manager%' and
counter_name = 'Page life expectancy'
Tak sme zistili počet pripojení na IIS z aplikačného servera: Start – Programs – Accessories – Performance. Tam sme vytvorili novú reláciu a pridali snapshot Active X (System Monitor). V tomto monitore pridáme (ikonka plus) objekt „Web Service“ a napríklad „Current Connections“ pre konkrétny IIS virtual directory. U nás boli podstatné všetky, lebo každa aplikácia používala jediný DB server. Taktiež potom bolo nutné upraviť vlastnosti grafu aby maximálna os nebola len 100, pretože spojení bolo viacej.
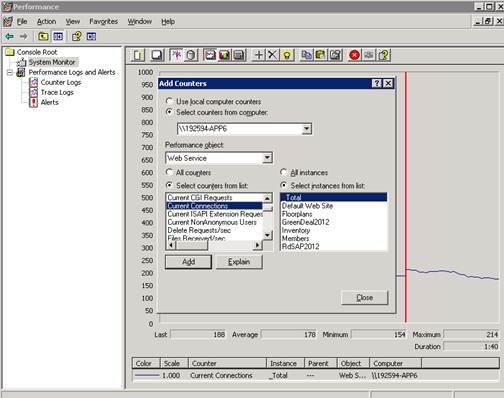
Po monitoringu sme zistili, že server je ako tak v pohode do 150 spojení. Nad 170 začínajú byť problémy (niekedy už 100% CPU) – záleží od toho čo vlastne užívatelia samozrjeme robili a pri 190 spojení bol server definitívne odpálený.
Z tohto monitora sa dá aj zistiť, ktorá DB je ako vyťažovaná. U nás sa ukázala jedna DB ako zdroj problémov – ale to sme vedeli aj bez toho a teda sme sa sústredili na jedinú databázu.
Taktiež môže byť zaujímavý TCP/IP transfer medzi DB a aplikačným serverom – u nás to ale nebolo hrdlo výkonu – týmto smerom sa optimalizácia neuberala.
Server veľmi swappoval na disku – boli zrejmé diskové I/O operácie. Mohlo to spôsobovať rýchle a krátke zápisy (u nás to robila hlavne session databáza – o tom nižšie), alebo veľa read operácii, ktoré vytláčali indexy z pamäti do swappu.
Vylúčiť software
Začali sme teda s najokatejšími vecami. Síce sme neočakávali úspech, ale išlo o „vylúčenie“ externalít. Hľadať jednorožce v jaskyni ak po lúke pobiehajú draky nemá zmysel.
Vedeli sme, že môžeme reštartovať SQL server (bez väčších škôd), tak sme to urobili. Chceli sme vylúčiť prípadne deadlock tranzakcie a o MSSQL 2005 je známe, že má problém s manažmentom pamäti – po čase leaky zaberú väčšinu toho, čo môže byť použité – nepomohlo.
Zistilo sa, že na serveri beží antivírus (WTF)? Keďže natvrdlé vedenie ani panovi ho nechcelo vypnúť, bolo nutné aspoň skontrolovať adresár, kde sa nachádzali databázy – či je v ignore liste. To by vysvetľovalo I/O diskové operácie (antivírus zakaždým kontroloval databázy). Adresár v ignore liste ale už bol.
Ďalším procesom, ktorý kafral do výkonu bol Double Take – zálohovací systém, ktorý on-line replikoval dáta. Keďže sa u nás nejedná o bankový systém a prípadna strata dát nie je až takým rizikom (ako odlev zákazníkov), zálohovanie sa vyplo – server sa občas „nadýchol“ – ale nič výrazne sa neudialo.
Prvá pomoc
Takže sme zistili, že za 5 minút to vyriešiť nevieme. Pred tým, ako sme sa pustili do analýzy museli sme nechať server trocha dýchať. Vedenie, užívatelia a proste všetci veľmi tlačili a prevádzka nemôže byť dva týždne odstavená.
Ako prvé, treba zistiť, či nejaký selekt neodpálil server. Na našom serveri bežalo niekoľko desiatok databáz. Medzi nimi boli aj malinké (nie veľmi dôležité) systémy. Teda také, ktorým sa veľmi nevenuje pozornosť a úlohy sa dávajú juniorom, neraz bez dohľadu niekoho zodpovedného. Toto zvykne byť zdrojom detonátorov (pozri nižšie). Môže tam byť nejaká štatistika, ktorá dostane server za hranicu výkonu (aj keď bez tejto štatistiky bežná prevádzka robustných aplikácii vykazovala len 50% výkonu)! Treba teda zistiť, čo tam aktuálne beží, napríklad týmto príkazom:
SELECT
p.spid,
right(convert(varchar, dateadd(ms, datediff(ms, P.last_batch, getdate()), '1900-01-01'), 121), 12) as 'batch_duration',
P.program_name,
P.hostname,
P.loginame
FROM master.dbo.sysprocesses AS P
WHERE
P.spid > 50 and
P.status not in ('background', 'sleeping') and
P.cmd not in
('AWAITING COMMAND',
'MIRROR HANDLER',
'LAZY WRITER',
'CHECKPOINT SLEEP',
'RA MANAGER')
ORDER BY
batch_duration desc
Pár krát sme si dali zobraziť zoznam a zistili sme, že tam stále zotrvávajú práve dva divne connecty z malých databáz. Okamžite sme ich odpálili (príkaz KILL {SPID}). Bežali niekoľko hodín a teda užívateľ i tak dostal time-out napr. z proxy). Ak toto pomôže serveru sa nadýchnuť, situácia nie je až taká vážna a treba sa zamerať na detonátory. No ak nestíha železo riadnu prevádzku, treba pátrať ďalej.
Nechápal som, ako z mesiaca na mesiac mohol server takto skolabovať. Začali som pátrať po odpovediach. Marketing chytil nového zákazníka, ktorý doteraz len dáta zbieral. Poslali nám ich a my sme ich púšťali v dávke do systému (čím skôr kôli fakturácii). Toto muselo teraz počkať – zastavili sme hromadné operácie (ktoré pôsobili ako DDoS útok).
Keďže sa jednalo o Win2003 Standard 32b a bolo tam 4GB RAM – bolo to fyzické maximum, ktoré OS dokázal zvládnuť. No MSSQL mal pridelených 1,5GB. OS zbytok aj tak nepoužíval. Preto sme prerobili manažment pamäti. MSSQL sme pridelili 2.5 GB a OS sa znížil na 1GB. Nad 2GB je potrebné zapnúť AWE.
Začali sme analyzovať čo za databázy tam vlastne sú a či nevieme niektoré aplikácie jednoducho dočasne vypnúť. Vždy sú tu kľúčové systémy a potom systémy, ktoré je fajn že mamé (niečo si kedysi niekto „z hora“ presadil). Tieto hlúposti spravidla neohrozuju business je a tak sme ich dočasne vypli. Jedna z databáz, ktorá tam bežala bola Session State DB. Naše webove systémy ukladali session v databáze. Keďže tam bol dosť vysoký TCP/IP transfer a potenciálne aj I/O operácie, okamžite sme presunuli session databázy na jeden z aplikačných serverov. Toto bola pomerne výrazne odľahčenie („EKG“ CPU už bolo zreteľnejšie). Mohli sme sa spolu so serverom už nadýchnuť aj my...
Analýza
Nastal čas analýzy. Existuje tuningový analyzátor pre MSSQL, ktorý zbiera dáta zo živej prevádzky a potom navrhne zmeny v databáze (indexy apod.). Toto bola slepá ulička. My sme nepotrebovali zrýchliť existujúcu infraštruktúru pridávaním indexov, práve naopak. Priveľa indexov (používaných) v pamäti mohlo spôsobovať konkurenčný boj o tých pár voľných megabajtov a OS pri nedostatku šiel do swappu čo v konečnom dôsledku mohlo byť pomalšie ako práca bez indexov (ak sa už server dostane do výkonnostnej „špirály“).
Na to sme teda použili priamo SQL príkaz (pracujeme s master db):
select top 10
sum(qs.total_worker_time) as total_cpu_time,
sum(qs.execution_count) as total_execution_count,
count(*) as number_of_statements,
qs.plan_handle
from sys.dm_exec_query_stats qs
group by
qs.plan_handle
order by
sum(qs.total_worker_time) desc
Queries sa dajú zobraziť podľa PlanHandle UID:
SELECT * FROM sys.dm_exec_query_plan (0x06000100A27E7C1FA821B10600)
Detonátory
V každom systéme sa nájdu nejaké staré časti systémov, ktoré sú chybné, na ktoré sa zabudlo apod. Kým je prevádzka a pamäť stabilná, tieto časti sa na výkone neprejavia. Ak sa ale dostane server na úroveň swappovania a CPU prestáva stíhať, práve títo zradcovia môžu pôsobiť ako rozbuška, ktorá dostane server do 100% vyťaženia. Pod detonátorom rozumiem tie dotazy, ktoré nie sú volané tak často, ale žerú ohromný čas.
Zistili sme, že sa jedná o také časti systému, ktoré boli robené len z „roztopaše“ vedenia (toto chcem a basta) a prakticky s minimálnym dopadom na užívateľa, ale extrémnym na výkon (business benefit nie je nikdy výkon... až kým sa věstko neposerie... všakže... a developer je len lenivý keď sa stavia na zadné, že nová vlastnosť je totálna hlúposť).
Tieto časti systému sme okamžite zneprístupnili. Taktiež sa našlo pár úchyliek typu, vo filtračnom module sa narátavá počet záznamov už pri vstupe (a keďže filter nebol aplikovaný, tak sa rátali všetky jeho dáta), taktiež po každej zmene filtra (či už string alebo dátum). Takéto blbosti sa proste vyhodili z aplikácie. CPU servera bolo už čoraz menej kontinuálnych 100%. Poriedili sa indexy a k ním napr. aj príslušne vyhľadávania apod.
Optimalizácia
Nastal čas prechádzať tie queries, ktoré aj keď netrvajú dlho, spúšťané veľmi veľa krát. Išli sme zaradom, tieto zmeny väčšinou sú dlhšie a vyžadujú aj povolenie manažmentu, lebo sa niekedy musí upraviť logika procesov.
Postupne sme vždy releasovali zmeny (normálne nám to trvá týždne, teraz boli všetci pokakaní, tak devloperom do toho nekecali). Prakticky každá úprava znamenala lepšiu kondíciu „EKG“. Jedna ale mala fatálny vplyv. Pracovali sme s GUIDom v retazci ako unique key. Z aplikácie sa k nemu pristupovalo napr. command.Parameters.AddWithValue(). Nič čudné... no v DB (kvôli veľkosti indexu) to nebol NVARCHAR ale CHAR. Stringy z .Netu šli v defaultnom kódovaní čo malo za následok, že databáza každy jeden GUID castila na NVARCHAR! Takáto úprava (vynútenie typu parametra z aplikácie) znamenala pokle vo výkone asi o 60%! Zrazu server nemal čo robiť a my sme začali postupne zapínať pomocné programy (zálohovač) a sprístupňovať časti sýstémov, ktoré sme zakázali.
Resumé
To, že systém už funguje sa dalo overiť jednoducho – zákazníci prestali volať a manžment začal uvažovať nad novými sprostosťami, ktoré budú budúcimi kandidátmi na detonátory... Ale keďže sme mali čísla, vedeli sme exaktne povedať, že stránka sa drží v pamäti počas peaku na 300 a mimo peaku cez 1000ms (čo je dôkaz, že sa neswapuje).
Taktiež CPU „EKG“ je prekrásne – nie pri počte 190 connections, ale pri 360 a viac:

Príloha
Ešte môže byť zaujímavý query na zistenie aktuálnych queries. Ak sa napríklad server občas dostane do „kómy“ (dočasne), dá sa zistiť čo tam vlastne beží:
SELECT
start_time,
status,
command,
Plan_Handle
FROM sys.dm_exec_requests
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
Taktiež si treba uvedomiť, že tie štatistky sú dostupné od posledného reštartu SQL služby. Ak sa ale výrazne prerobia prístupy k dátam, tieto zmeny kvôli starým údajom budu dočasne skreslené. Preto je niekedy vhodne reštartovať štatistiky napr. takto:
dbcc freeproccache